PerSpinasAdAstra
Well-Known Member
- Relationship to Diabetes
- Type 2
- Pronouns
- He/Him
The original conversation in this thread began here and has been split so each topic has it's own focus. https://forum.diabetes.org.uk/board...port-lack-thereof-for-ble-cgm-profile.115492/
Edit made by @Anna DUK.
Off topic but as Garmin devices are mentioned I have a query:
I'm currently learning Python with the intention of writing some software to help analyse CGM, exercise and meal data. Still very early days. At present the simplest approach I've come up with is to take CGM data from Tidepool (using that system to collect CGM and glucometer data and using their CSV/JSON export function so that I don't have to parse data from many different devices separately), exercise data from Fitbit/Garmin, and meal data from a food tracking app with a function to export to CSV. On the exercise side I was thinking of taking advantage of this project which downloads from Garmin Connect and dumps the data into a SQLite database:
GitHub - tcgoetz/GarminDB: Download and parse data from Garmin Connect or a Garmin watch, FitBit CSV, and MS Health CSV files into and analyze data in Sqlite serverless databases with Jupyter notebooks.
Download and parse data from Garmin Connect or a Garmin watch, FitBit CSV, and MS Health CSV files into and analyze data in Sqlite serverless databases with Jupyter notebooks. - tcgoetz/GarminDB
 github.com
github.com
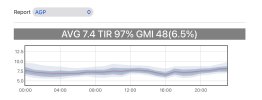
Basically the idea is to collect as much relevant data as possible and then try to generate fancy graphs and display relevant information and statistics relating to the factors that might have influenced the shape of those graphs. I want to try to observe the degree to which exercise, sleep quality and duration, stress, steps, medications etc. affect the CGM graphs associated with many near-identical meals, and to better observe changes in the nature of my diabetes over time. I believe that in the long-term developing ways to gather and analyse this kind of data might help to answer some question about T2 progression and remission - how much exercise is enough, are some diet approaches better than others, how much weight loss after diagnosis is enough, how important is it to build and maintain muscle mass, is it actually a good idea to go off medications completely after big weight loss if HbA1c suggests medications are unecessary - that kind of thing.
My query is: would such software be of any interest to T1s using Garmin devices while cycling or running or whatever? Is retrospective data analysis which includes a comprehensive exercise component of any use to you? I have almost zero knowledge of insulin therapy and so I have no idea if including the capability to display insulin data would be of any use to anyone. The Tidepool data export does include comprehensive insulin data, where available, but has no facility to track exercise and so I wonder, does that mean nobody cares? Should I just focus on creating the software that I wish I had for my own purposes or should I try to incorporate all the insulin data that Tidepool can give me because Garmin data plus insulin data might be useful to someone?
Last edited by a moderator: